

Alan Turing, célèbre mathématicien et cryptologue britannique, dont les travaux ont abouti au fondement scientifique de l’informatique et à certaines des premières recherches avancées sur l’intelligence artificielle a déclaré : « La question, les machines peuvent-elles penser ? », n’est pas suffisamment pertinente pour que l’on en débatte.
Je pense néanmoins qu’à la fin du siècle, l’usage des mots et le niveau général de culture auront tellement évolué que l’on pourra parler de machines pensantes sans crainte d’être contredit. ».
Voilà une sage parole… L’intelligence artificielle (IA) n’a jamais connu autant de définitions différentes, et même fluctuantes. Sitôt qu’un ordinateur ou un algorithme a atteint un objectif pour lequel nous estimions qu’un certain niveau d’intelligence était requis, nous nous ravisons et prétendons qu’il ne s’agit pas là d’intelligence. Les définitions de l’IA axées sur l’aspect procédural ou structurel se perdent la plupart du temps dans des considérations philosophiques fondamentalement insolubles pour l’esprit. Ces définitions ne nous aident pas à comprendre comment bâtir des systèmes intelligents ni à décrire ceux que nous avons déjà élaborés. Une fois de plus, on perd l’objectif de vue. Bien que souvent présenté comme un test d’intelligence des machines, le test de Turing est justement une tentative de son concepteur, Alan Turing, d’éluder la question. L’intelligence est une notion sous-déterminée et vague d’un point de vue sémantique. Au fond, qu’une machine soit intelligente ou non, cela importe peu.
Au final, c’est une simple question de convention. Cela a à peu près autant de sens que de se demander si les sous-marins nagent ou si les avions volent vraiment. Pour Turing, l’important n’est pas la façon dont nous désignons les capacités d’une machine, mais bien les limites de ce qu’elle est capable d’accomplir.
L’intelligence des machines se mesure à ce qu’elles peuvent nous faire croire
Notre meilleure chance de savoir si les machines pensent comme les humains est donc de déterminer dans quelle mesure elles peuvent le leur faire croire. Turing et la définition fournie par les organisateurs de la première conférence sur l’IA en 1956 suggèrent que « chaque aspect de l’apprentissage ou toute autre caractéristique de l’intelligence peut être si précisément décrit qu’une machine peut être conçue pour le simuler ». Pour chaque tâche arbitraire qu’un être humain doit exécuter, l’IA devrait être à même de simuler les performances ou les comportements humains avec un degré arbitraire de précision. C’est ce que le test de Turing a tenté de démontrer en analysant jusqu’à quel point une machine ou un ordinateur pouvait se faire passer pour un humain auprès d’un observateur dans le cadre d’une conversation non structurée. Dans la version du test de Turing, la machine devait faire croire à l’observateur qu’elle était une femme.
Ces dernières années, la combinaison de puissantes techniques d’apprentissage automatique et d’une énorme masse de données d’apprentissage a permis à des algorithmes de tenir des conversations nécessitant peu ou pas de compréhension. Mieux encore, de petites astuces, qu’aucun observateur humain ne considérerait comme des preuves d’intelligence, telles que des fautes d’orthographe ou de grammaire aléatoires, aident les algorithmes à passer pour des ersatz humains de manière de plus en plus convaincante. De nouveaux tests de compréhension humaine, comme les schémas de Winograd, proposent d’interroger une machine sur sa connaissance du monde, sur l’usage et les fonctions des objets, avec des questions à la portée de tout être humain.
À la question : « Le trophée ne rentrait pas dans le sac parce qu’il était trop grand. Qu’est-ce qui était trop grand ? », n’importe qui répondrait sans hésiter « le trophée ». Introduisons maintenant une variante : « Le trophée ne rentrait pas dans le sac parce qu’il était trop petit. Qu’est-ce qui était trop petit ? ». Dans ce cas, la réponse est clairement « le sac ». Ces tests plus précis analysent le type de connaissances qu’une machine doit avoir du monde pour s’attaquer à des questions auxquelles de simples techniques d’exploration des données ne permettent pas de répondre. Une telle définition suppose que l’IA peut simuler n’importe quel aspect du comportement humain. Elle se distingue en cela des systèmes d’IA conçus pour accomplir des tâches spécifiques de manière intelligente.
Non, l’apprentissage n’est pas obligatoirement une caractéristique de l’IA
L’IA générale ou AGI (Artificial General Intelligence), est ce à quoi les gens font généralement référence lorsqu’ils parlent d’IA. Il s’agit des robots qui, dans l’imaginaire collectif des films et de la littérature, dirigeront un jour le monde et régneront en maîtres. L’essentiel de la recherche dans ce domaine porte sur les systèmes d’IA appliquée, c’est-à-dire spécifiques. Cela va des systèmes de reconnaissance vocale et de vision par ordinateur mis au point par Google et Facebook, à l’IA pour la cybersécurité développée par des éditeurs spécialisés. Les systèmes d’IA appliquée utilisent en principe différents algorithmes, dont la plupart sont conçus pour s’adapter au fil du temps et exécuter des tâches spécifiques avec davantage de performances à mesure que le système reçoit de nouvelles données.
La capacité d’adaptation ou d’apprentissage en réponse à de nouvelles informations est l’une des caractéristiques qui définissent le cadre de l’apprentissage automatique. Toutefois, il ne s’agit pas d’une condition indispensable à un système d’IA. À l’instar de Deep Blue pour les échecs, certains systèmes d’IA fonctionnent avec des algorithmes qui ne requièrent aucun apprentissage. Néanmoins, leur champ se limite généralement à des environnements et problématiques bien définis. En fait, les systèmes experts, fondements de la bonne vieille intelligence artificielle (ou GOFAI pour Good Old-Fashioned AI), reposent sur une connaissance préprogrammée basée sur des règles, plutôt que sur une alimentation continue de données. Il est admis que l’IA générale, de même que les tâches d’IA appliquée les plus courantes, exigent au moins une forme d’apprentissage automatique.
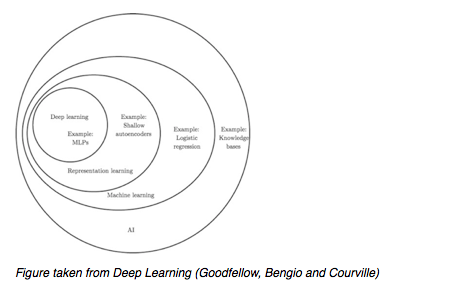
La figure ci-dessus illustre la relation entre l’IA, l’apprentissage automatique et l’apprentissage profond (ou deep learning). L’apprentissage profond est une forme spécifique d’apprentissage automatique. Bien que nécessaire aux tâches d’IA les plus avancées, l’apprentissage automatique, en soi, n’est pas une fonction ni une caractéristique essentielle de l’IA. L’apprentissage machine est requis pour simuler les aspects les plus simples de l’intelligence humaine, pas les plus complexes. Par exemple, le programme d’IA Logic Theorist conçu par Allen Newell et Herbert Simon en 1955 a démontré 38 des 52 premiers théorèmes des Principia Mathematica sans aucun apprentissage.
Le développement de programmes capables de reconnaître la parole ou d’identifier des objets sur des images est une tâche encore plus complexe. Ce sont pourtant des opérations relativement simples pour l’homme. Même s’il s’agit de tâches intuitivement simples pour les humains, toute la difficulté réside dans l’impossibilité de créer un ensemble de règles simples permettant d’identifier des phonèmes, lettres et mots dans des données acoustiques. C’est aussi pour cela qu’il est difficile de définir l’ensemble de caractéristiques de pixels qui distinguent un visage d’un autre.
La figure ci-dessous, extraite de l’article Pattern Recognition and Modern Computers écrit par Oliver Selfridge en 1955, montre qu’une information en entrée peut prêter à différentes interprétations selon le contexte. Le « H » dans « THE », et le « A » dans « CAT », sont des ensembles de pixels identiques dont l’interprétation en H ou A dépend des lettres voisines plutôt que des lettres elles-mêmes.

Des machines qui apprennent à résoudre par elles-mêmes des problèmes offrent par conséquent de meilleurs résultats que celles qui se basent sur des solutions préconçues.